
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w+、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
@
前言:
嗨喽,大家好,今天为大家带来的是Python 基于 flask 的前程无忧招聘可视化系统,大数据招聘爬虫可视化分析,该项目使用 flask框架,Mysql 数据库,request,selenium 框架进行爬虫,实现招聘数据的采集,清洗等,该项目总体来说还是挺不错的,界面美观,下面针对这个项目做具体介绍。

1:项目涉及技术:
项目后端语言:python flask
项目页面布局展现:前端bootstrap
项目数据可视化呈现:html, css,echars
项目数据操作:mysql数据库
项目数据获取方式:爬虫(selenium)
Python Flask 简介及其优缺点
一、Flask 简介
Flask 是一个基于 Python 的轻量级 Web 框架,通常称为“微框架”。它由 Armin Ronacher 开发,最早于 2010 年发布。Flask 设计的初衷是为了提供一个灵活且简洁的框架,开发者可以根据需求构建各种 Web 应用程序。虽然 Flask 是“微框架”,但这并不意味着它功能不全,实际上它可以通过扩展轻松支持复杂的 Web 应用。
Flask 提供的核心功能非常精简,开发者可以根据需求自行添加数据库支持、身份验证等模块。这使得 Flask 成为快速原型开发和小型项目的理想选择。
Flask 的基本结构
Flask 的代码结构非常简单,可以用少量代码实现一个基本的 Web 应用。以下是一个典型的 Flask 项目结构:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, Flask!'
if __name__ == '__main__':
app.run(debug=True)Flask类用于创建应用对象app。@app.route('/')是路由装饰器,定义了 URL 与函数的映射关系。app.run()启动了应用程序并使其在开发服务器上运行。
这个简单的例子展示了 Flask 如何轻松创建一个 Web 服务器并处理 HTTP 请求。
二、Flask 的优点
2.1 简单易学
Flask 是一个非常简洁的框架,核心库只有少量的概念和功能。它没有 Django 那样的复杂性,非常适合初学者学习 Web 开发。通过 Flask,开发者可以快速上手,掌握基本的 Web 开发技能。
Flask 的 API 设计十分直观,使得编写代码变得更加简单:
@app.route('/about')
def about():
return 'This is the about page.'通过简单的装饰器语法,开发者可以轻松为不同 URL 定义不同的处理函数。
2.2 灵活性高
Flask 提供了极高的灵活性。它没有太多默认的设置和结构限制,开发者可以自由选择如何组织代码、使用哪些库和扩展。对于不同的项目需求,开发者可以根据具体情况自由定制项目架构。
Flask 允许开发者使用他们熟悉的工具和技术栈,例如 SQLAlchemy(数据库)、Jinja2(模板引擎)等。
2.3 丰富的扩展库
虽然 Flask 本身是一个轻量框架,但其社区非常活跃,提供了丰富的扩展库。开发者可以按需使用这些扩展库来补充功能,例如数据库 ORM、表单处理、身份认证等。
常见的 Flask 扩展库包括:
- Flask-SQLAlchemy:用于数据库操作的 ORM(对象关系映射)工具。
- Flask-WTF:用于处理表单的扩展。
- Flask-Login:处理用户登录与认证的扩展。
这些扩展使 Flask 具有了足够的灵活性和强大功能,可以应对各种复杂的 Web 应用开发需求。
2.4 适合快速开发和原型设计
Flask 非常适合快速开发和构建原型。由于它简单、轻量且灵活,开发者可以在短时间内快速搭建一个基本的 Web 应用,这对于早期阶段的产品验证、测试和演示非常有帮助。
对于初创公司或需要快速迭代的项目,Flask 是一个不错的选择。
2.5 强大的模板引擎支持
Flask 使用 Jinja2 作为其模板引擎,这使得开发者可以在 HTML 文件中使用模板语法生成动态内容。Jinja2 模板引擎功能强大,支持条件判断、循环、过滤器等操作,使得前后端代码更容易维护和分离。
例如,下面是一个使用 Jinja2 的模板代码:
<!DOCTYPE html>
<html>
<head>
<title>{{ title }}</title>
</head>
<body>
<h1>Hello, {{ name }}!</h1>
</body>
</html>在 Flask 代码中渲染这个模板:
from flask import render_template
@app.route('/greet/<name>')
def greet(name):
return render_template('greet.html', title='Welcome', name=name)三、Flask 的缺点
3.1 功能较为基础
与 Django 这样的全栈框架相比,Flask 的默认功能相对基础。它不会内置很多 Web 开发常用的功能,如用户认证、后台管理、ORM 等。开发者需要自行选择扩展库并进行集成。
虽然这增加了灵活性,但对于新手来说,这也意味着更多的配置和学习成本。如果你的项目需要复杂的功能,你可能需要在 Flask 基础上额外集成很多库。
3.2 大型项目维护难度较高
对于大型项目来说,Flask 的简单和灵活有时会带来维护上的挑战。由于 Flask 没有强制的项目结构和开发模式,不同的开发者可能会以不同的方式组织代码。这在小型项目中是优势,但当项目变大时,缺乏一致性可能会导致维护困难。
而像 Django 这样的大型框架,会有更加统一和规范的项目结构,适合大型团队合作开发和长期维护。
3.3 没有内置的数据库管理功能
Flask 不像 Django 那样内置了强大的 ORM 和数据库迁移工具。虽然 Flask 可以通过扩展(如 Flask-SQLAlchemy)集成数据库功能,但这需要额外的配置和学习。而 Django 的 ORM 系统内置了强大的模型管理和迁移功能,使数据库操作更为方便。
3.4 社区与生态系统规模较小
尽管 Flask 的社区相当活跃,但与 Django 这样的框架相比,其生态系统的规模和成熟度相对较小。特别是一些针对企业级应用的高级功能,Django 提供的解决方案可能更为成熟和稳定。
四、总结:Flask 的适用场景
4.1 适用场景
- 快速原型开发:如果你需要在短时间内快速搭建一个 Web 应用,Flask 是一个不错的选择。它简单易用,能够帮助你快速实现基本的功能。
- 小型项目:对于个人项目或中小型应用,Flask 足够轻量且灵活。你可以根据项目需求,自由选择扩展库来补充功能。
- 微服务架构:Flask 因为轻量化设计,也非常适合微服务架构。你可以将不同的服务模块化,各自独立开发和部署。
4.2 不适用场景
- 大型企业级应用:对于复杂的大型应用,特别是团队开发时,Django 可能是一个更合适的选择。Django 提供了更多内置功能和更强的约定,适合规模化开发和维护。
- 需要内置管理功能的应用:如果你的项目需要用户管理、权限控制、后台管理等功能,Django 可能会更加方便,因为这些功能在 Django 中是开箱即用的,而 Flask 需要通过扩展和自定义实现。
总的来说,Flask 是一个灵活、轻量、简单的 Web 框架,适合快速开发和小型项目。但在面对更复杂的应用场景时,可能需要更为完善的全栈框架如 Django。
Python 爬虫功能实现
Python Selenium 是一个自动化测试工具集合,主要用于Web应用程序的测试。Selenium 可以模拟用户在浏览器中的行为,如点击、滚动、键入等,因此它也常被用于Web爬虫的开发,尤其是对于那些需要与JavaScript交互的动态网页。
Selenium 简介
Selenium 支持多种编程语言,包括 Python、Java、C# 等。在 Python 中,Selenium 提供了一个简单的 API 来编写测试脚本。Selenium 通过 WebDriver 与浏览器进行交互,WebDriver 是一个浏览器自动化的驱动程序,Selenium 支持所有主流浏览器,如 Chrome、Firefox、Safari、Edge 等。
Selenium 的主要组件
- WebDriver:直接与浏览器进行交互的接口。
- Remote WebDriver:允许你通过 Selenium Server 在不同的机器上运行测试。
- Selenium API:提供了一组简单的命令来控制 WebDriver。
如何使用 Selenium 爬虫
使用 Selenium 进行爬虫的基本步骤如下:
-
安装 Selenium:在 Python 环境中安装 Selenium 库。
pip install selenium -
下载 WebDriver:根据你使用的浏览器,下载对应的 WebDriver。例如,如果你使用 Chrome 浏览器,你需要下载 ChromeDriver。
-
编写爬虫脚本:使用 Selenium 的 API 编写爬虫脚本,模拟用户行为获取动态内容。
-
运行爬虫:执行脚本,Selenium 将自动打开浏览器,模拟用户操作,获取网页数据。
下面是一个简单的 Selenium 爬虫示例:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# 初始化 WebDriver
driver = webdriver.Chrome('/path/to/chromedriver')
# 打开网页
driver.get('http://example.com')
# 等待页面加载
time.sleep(3) # 简单睡眠等待,实际应用中应使用更智能的等待条件
# 找到元素并进行操作,例如输入文本
element = driver.find_element_by_name('q')
element.send_keys('Python')
element.send_keys(Keys.RETURN)
# 等待搜索结果
time.sleep(3)
# 获取搜索结果页面的标题
print(driver.title)
# 关闭浏览器
driver.quit()注意事项
- 遵守 robots.txt:在进行爬虫之前,应该检查目标网站的
robots.txt文件,以确保你的爬虫行为是被允许的。 - 设置合理的请求频率:避免对目标网站服务器造成过大压力。
- 异常处理:在爬虫中添加异常处理逻辑,确保在遇到错误时能够正确处理。
- 数据解析:获取到的网页内容通常需要进一步解析,可以使用 BeautifulSoup、lxml 等库来提取所需数据。
Selenium 爬虫适用于那些需要模拟用户交互才能获取数据的网站,但它通常比纯粹的 HTTP 请求库(如 requests)慢,因为它需要启动浏览器实例。因此,对于静态内容的抓取,通常推荐使用更轻量级的方法。
3:项目功能:
1 登录注册
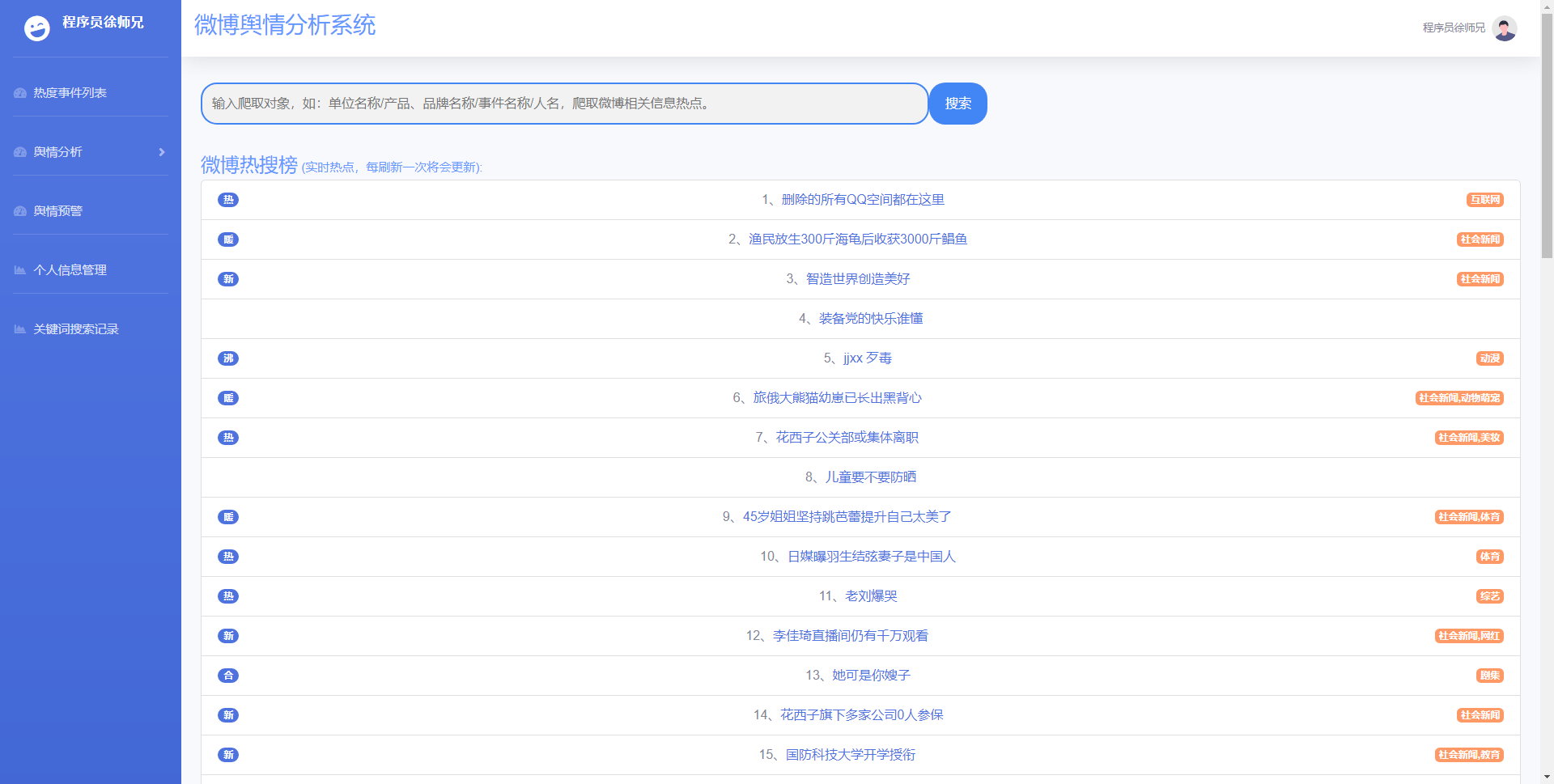
爬取数据后启动项目会把数据都存放在数据库里,(数据库有3个表,一个工作岗位信息表,一个用用户信息表,一个工作收藏表),然后进入项目的登陆注册页面,以及会对用户的账号密码经行校验和存储,校验成功后进入首页:
首页招聘数据
招聘数据
这里的招聘数据,是我们爬虫的数据,存储在 mysql 数据库当中,如果我们想要展示,可以通过读取数据库进行展示,同时进行分页
招聘数据可视化
4 推荐阅读
5 源码获取:
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人







暂无评论内容